Modern Frameworks for Modern Alerting
A presentation at PagerDuty EMEA Summit 2020 by Daniel "phrawzty" Maher

Modern frameworks for modern alerting Daniel Maher @phrawzty Ara Pulido @arapulido

Datadog is a monitoring and analytics platform that helps companies improve observability of their infrastructure and applications

Daniel Maher, Developer Relations dan.maher@datadoghq.com @phrawzty Ara Pulido, Technical Evangelist ara.pulido@datadoghq.com @arapulido

Endpoint foobar is unavailable

Logs

Logs Infrastructure metrics

Logs Work metrics Infrastructure metrics

Logs Work metrics RUM data Infrastructure metrics

RUM Logs data Resource metrics Work metrics Infrastructure metrics

RUM Logs data Resource metrics Work metrics Infrastructure metrics Traces

RUM Logs data Resource metrics Work metrics Infrastructure metrics Events in our app Traces

RUM Logs data Resource metrics Infrastructure metrics Events in our app Traces Work metrics AI/ML aggregated data

Browser/UI tests RUM Logs Infrastructure data metrics Resource metrics Events in our app Traces Work metrics AI/ML aggregated data

Browser/UI tests RUM Logs Infrastructure data metrics Resource Business metrics Events in metrics our app Traces Work metrics AI/ML aggregated data

Browser/UI tests RUM Logs Infrastructure data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data

Browser/UI tests RUM Logs Infrastructure data Networking data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data

Security RUM Browser/UI tests Logs Infrastructure data Networking data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data
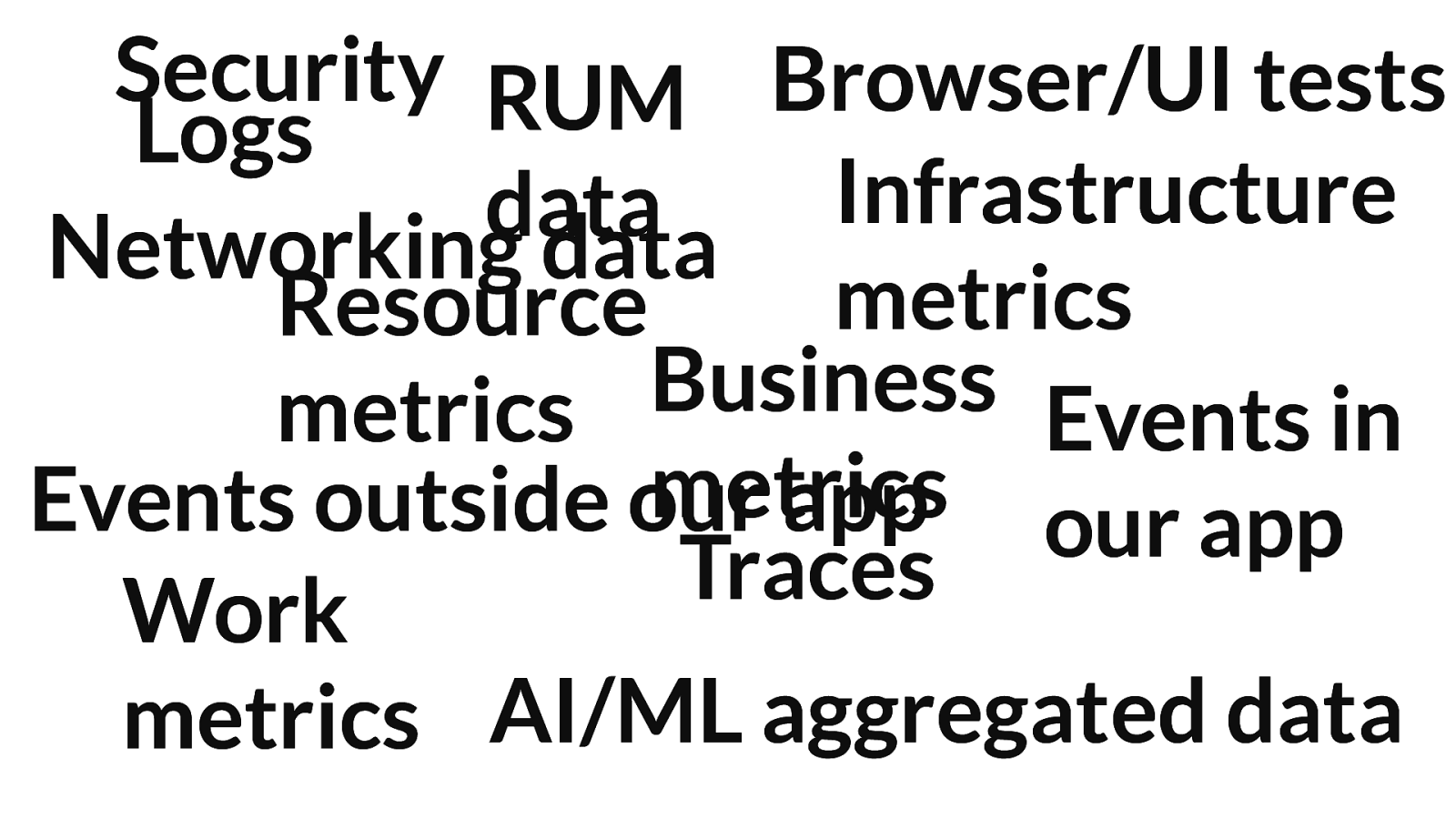
Security RUM Browser/UI tests Logs Infrastructure data Networking data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data

Security RUM Browser/UI tests Logs Infrastructure data Networking data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data FOUR

Security RUM Browser/UI tests Logs Infrastructure data Networking data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data FOUR GOLDEN

Security RUM Browser/UI tests Logs Infrastructure data Networking data metrics Resource Business metrics Events in metrics Events outside our app our app Traces Work metrics AI/ML aggregated data FOUR GOLDEN SIGNALS


Alert Fatigue

Information Overload

Service Level Indicators Objectives Agreements

Alerts Pages


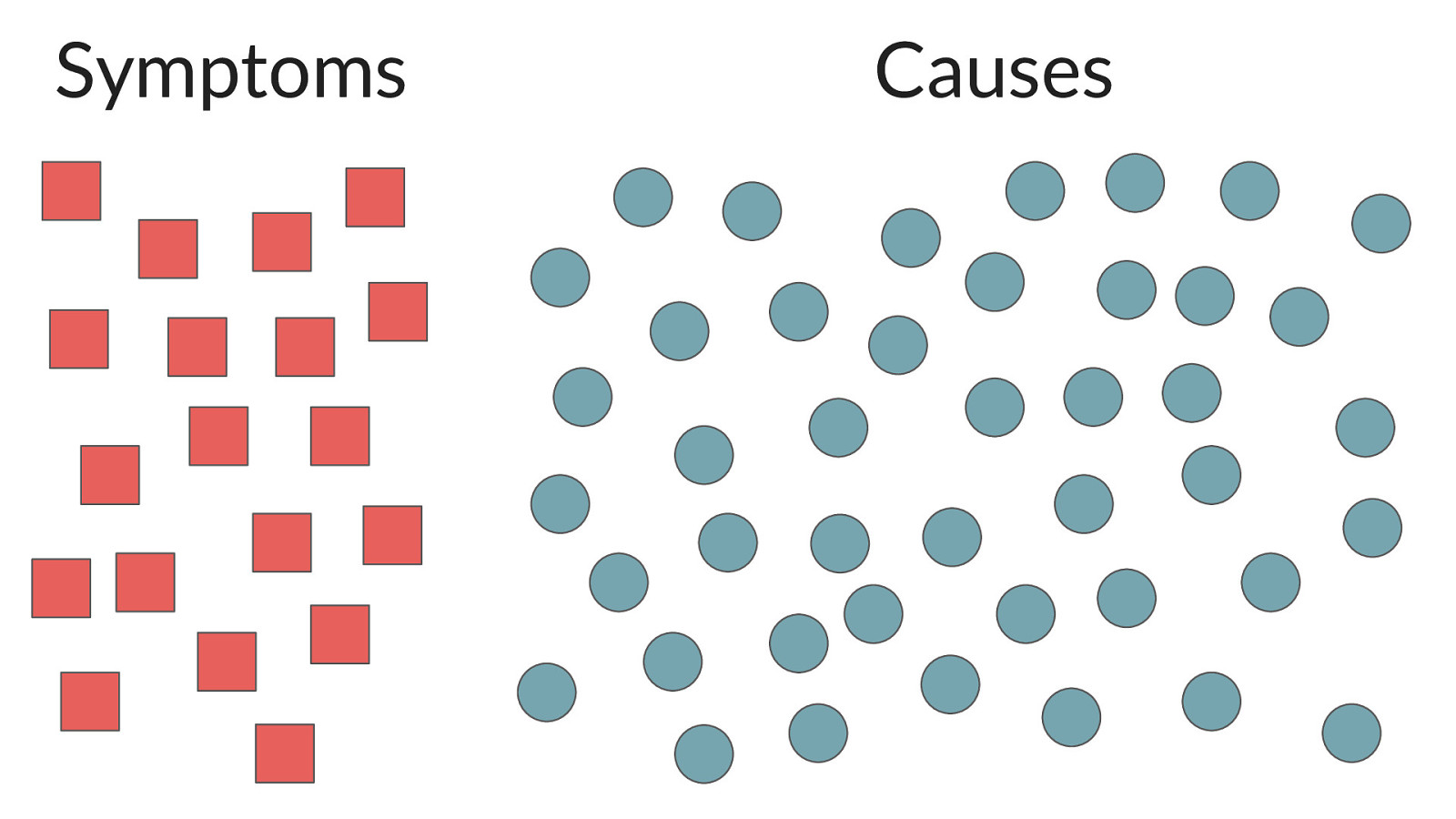
Symptoms vs. Causes

Symptom 18 % of queries are returning an error

Cause 3 nodes of the cluster are down

It is so tempting to page on causes

DON’T

SLAs are written based on symptoms
Symptoms Causes

Urgency


High p99 latency > 100ms

Only page on these Related to your SLOs

Medium 1 node of the cluster is down

Notify on these

Low Database I/O is slower than usual

Log these

Symptoms Causes

Error Budget

Urgency; but make it (error) budget

SLOs & SLAs Alert or Page?


Availability vs. Accessibility

Organise data by team
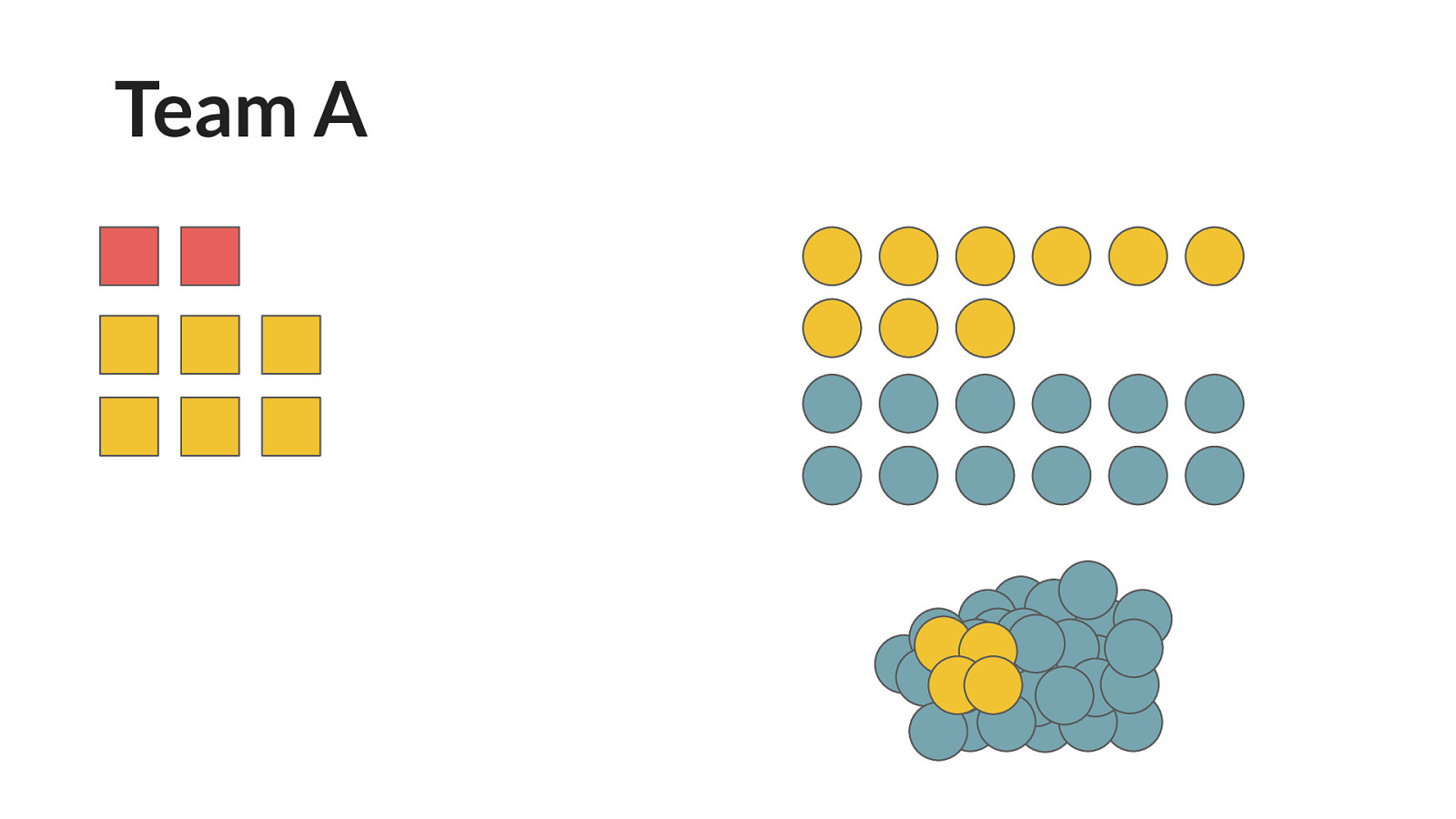
Team A

Information Underload (?)

Thank you! https://www.datadoghq.com Daniel Maher @phrawzty Ara Pulido @arapulido

Monitoring is an ancient discipline—but one that has evolved significantly in the past few years. Modern monitoring platforms collect a lot of data from our systems: work and resource metrics, events that are happening inside and outside our applications, distributed tracing data, real user monitoring, and more. But are we using all that data in a way that helps to avoid outages without causing alert fatigue? Are we suffering from information overload in our monitoring systems? We’ll present strategies on how to organise your system data in a way that helps your teams anticipate future user-facing issues and avoids alert fatigue by paging only when immediate attention is required.
Buzz and feedback
Here’s what was said about this presentation on social media.